这个问题可能比较简单,但是也算是一点感悟吧。我们来看个例子(来自:http://blog.csdn.net/acdreamers/article/details/44661149):

当前信息的熵计算如下:
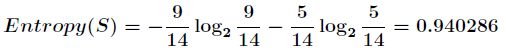
再看下,按照outlook分类后的例子:

分类后信息熵计算如下:



代表在特征属性 的条件下样本的条件熵。那么最终得到特征属性
的条件下样本的条件熵。那么最终得到特征属性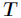 带来的信息增益为
带来的信息增益为

信息增益的计算公式如下

好吧,抄别人的东西到此为止了:
这里要说的是为什么分类多了信息熵会减少????????????
我们从概念和功能上分析:物体越不稳定或者可能性越多或者成分越复杂,越不确定信息熵就越大,因此我们对
物体进行分类后,物体成分逐渐变得简单(pure),所以熵就减少啦。
最大的熵出现在每种情况发生概率相同的时候。
信息熵的定义:
